
Enhance EF Core Performance (Part I)
Entity Framework Core (EF Core) is an amazing tool that simplifies database access. But there’s nothing more frustrating than seeing your app slow down because of poorly optimized database queries.
In this post, I will share a list of tips to help you optimize EF Core for maximum performance. So, let’s get started and transform your application into an optimized and high-performance solution!
DBContext Pooling
One of the first and most effective ways to boost EF Core performance is by leveraging DbContext pooling. As your application grows, creating and disposing of DbContext instances can become a costly operation, especially under heavy load. This is where DB context pooling comes in by reusing existing DbContext instances, it minimizes the overhead and improves scalability.
With DbContext pooling, EF Core maintains a pool of DbContext instances that are reused across requests. This reduces the time spent on instantiating new contexts and helps keep your application fast and responsive, even as the load increases.
Implementation
To enable context pooling, simply replace AddDbContext with AddDbContextPool
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDbContextPool<ApplicationDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection")));
// Add services to the container.
var app = builder.Build();
// Configure the HTTP request pipeline.
app.Run();
By pooling DbContext instances, you ensure that each request gets a context that’s already initialized.
The poolSize parameter in AddDbContextPool defines the maximum number of DbContext instances the pool will retain (default is 1024). If this limit is exceeded, new context instances won’t be cached, and Entity Framework will revert to creating instances on demand without pooling.
If you are developing a multi-tenant ASP.NET Core application please check this link to enable context pooling properly.
Benchmarks
In this section, we’ll compare the performance of DbContext pooling versus using a regular DbContext instance. To achieve this, I’ve utilized the DotNetBenchmark library to benchmark fetching a single row from a SQL Server database running locally, both with and without DbContext pooling.

From the table, we can clearly observe the following:
- WithContextPooling offers a slightly faster and significantly more memory-efficient solution compared to the WithoutContextPooling method.
- Although the time difference in this test is modest (0.391 ms), the reduced memory usage and improved garbage collection efficiency highlight the advantages of pooling, particularly in high-load scenarios or when dealing with large databases and frequent operations.
You can find the full source code for this benchmark here
Limitations
If you need to maintain long-lived DbContext instances that span multiple operations or transactions (such as in background jobs), pooling might not be suitable. This is because a pooled context may be reused across operations, potentially leading to inconsistent state.
When you need to run tasks in the background and need full control over the DbContext lifecycle, you can inject IDbContextFactory
public class MyBackgroundService : BackgroundService
{
private readonly IDbContextFactory<ApplicationDbContext> _contextFactory;
public MyBackgroundService(IDbContextFactory<ApplicationDbContext> contextFactory)
{
_contextFactory = contextFactory;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
// Create a new instance of the DbContext
using (var context = _contextFactory.CreateDbContext())
{
// Use the context as needed
var data = await context.MyEntities.ToListAsync();
// Perform your background task logic here...
}
}
}
For the above method to work, you must ensure that IDbContextFactory
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDbContextPool<ApplicationDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection")));
// Register IDbContextFactory to create new DbContext instances
builder.Services.AddDbContextFactory<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
// Add services to the container.
var app = builder.Build();
// Configure the HTTP request pipeline.
app.Run();
Compiled Queries
Compiled queries can provide a significant performance boost by reducing the overhead of query translation. Unlike regular LINQ queries, which are parsed and translated into SQL every time they are executed, compiled queries perform this translation once and reuse the compiled SQL for subsequent executions.
- Frequently Executed Queries: When the same query is executed repeatedly with varying parameters.
- Read-Intensive Applications: Applications with a high volume of read operations, such as reporting dashboards or analytics tools.
- Performance-Critical Scenarios: When CPU overhead for query translation needs to be minimized.
Implementation
To use compiled queries in EF Core, you can leverage the EF.CompileQuery method to create a compiled query delegate. Below is an example:
using Microsoft.EntityFrameworkCore;
public class CompiledQueryExample
{
// Define a compiled query
private static readonly Func<ApplicationDbContext, int, Task<MyEntity>> GetEntityByIdCompiledQuery =
EF.CompileAsyncQuery((ApplicationDbContext context, int id) =>
context.MyEntities.FirstOrDefault(e => e.Id == id));
public async Task<MyEntity> GetEntityByIdAsync(ApplicationDbContext context, int id)
{
// Use the compiled query
return await GetEntityByIdCompiledQuery(context, id);
}
}
Benchmarks
I conducted a benchmark to compare the performance of fetching the highest-rated blog using regular queries versus compiled queries. The benchmark measures execution time and memory allocation for both methods with different numbers of blogs. Below are the results:

The results clearly show that WithCompiledQuery is significantly faster than WithoutCompiledQuery, both for fetching a single blog and for retrieving multiple blogs. While both methods allocate similar amounts of memory, there is a slight reduction in memory usage with WithCompiledQuery. The difference in garbage collection (Gen0) is minimal in this case, as the overall memory allocation is relatively low.
You can find the full source code for this benchmark here
Limitations
When using parameters in compiled queries, it’s important to use simple, scalar parameters. More complex parameter expressions, such as member or method accesses on instances, are not supported. This means that you should pass basic data types like integers, strings, or booleans as parameters, rather than objects or expressions that reference instance members or methods.
var compiledQuery = EF.CompileQuery((ApplicationDbContext context, Blog blog) =>
context.Blogs.Where(b => b.Title == blog.Title));
// This will fail because 'blog.Title' is a member access and not a simple scalar parameter
var result = compiledQuery(dbContext, new Blog { Title = "EF Core" }); // 'blog' is an object
Split Queries
In EF Core 5.0 and above, a split query is the technique where multiple SQL queries are executed to retrieve related entities separately, rather than fetching all data in one single query (the default “eager loading” behavior). Split queries are particularly useful when you’re working with large collections and complex relationships.
By default, when you use methods like Include() to eagerly load related entities, EF Core will generate a single SQL query that joins all the tables. This can lead to performance issues when:
- The relationships involve large collections.
- The query results in a very large amount of data being transferred.
- Complex joins result in a cartesian explosion, increasing both the time to execute the query and the memory consumed.
Implementation
Split queries can be enabled by using the .AsSplitQuery() method. Here’s an example:
var blogsWithPosts = dbContext.Blogs
.Include(b => b.Posts) // Include related posts
.AsSplitQuery() // Use split queries for loading related entities
.ToList();
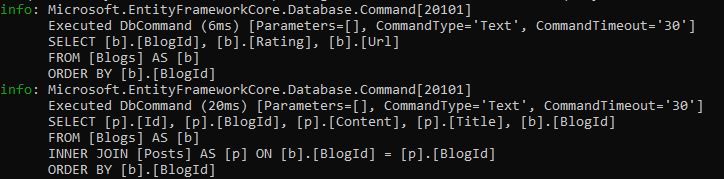
This query will result in two SQL queries:
- One query to retrieve all the blogs.
- Another query to retrieve all the posts related to those blogs.
Benchmarks
I prepared a benchmark where I create 10 posts for each blog and here are the results:

These results highlight the performance differences between using SplitQuery and the standard single query approach.
- For 1 blog: WithoutSplitQuery is faster, with a mean execution time of 7.487 ms compared to 11.942 ms for WithSplitQuery.
- For 10 blogs: The gap widens slightly, with WithoutSplitQuery taking 10.835 ms, while WithSplitQuery takes 14.273 ms.
In both cases, memory usage is similar, with WithSplitQuery showing a slight increase in memory allocation compared to the non-split approach, but the difference is not substantial.
The use of Split Queries should be carefully justified based on the specific scenario:
-
For fewer records: WithoutSplitQuery typically offers better execution time performance, though it may consume more memory due to row duplication in joins.
-
For larger datasets: WithSplitQuery can enhance memory efficiency by splitting the query into smaller parts, mitigating the risk of cartesian explosion. However, this comes with the trade-off of increased query execution time.
You can find the full source code for this benchmark here
Limitations
While Split Queries offer performance benefits in certain scenarios, they come with limitations that should be considered:
-
Cannot Be Used with Some Queries: Split queries are designed to work specifically with navigation properties that represent collections or one-to-many relationships. They cannot be applied to other types of queries, such as those involving aggregations or certain operations that require more complex logic.
-
Overhead for Small Data Sets: For queries involving small datasets, using Split Queries may introduce unnecessary overhead. The performance benefits, such as reduced memory usage, are less pronounced in these cases, making the extra complexity and processing less valuable.
-
Impact of Round Trips: When querying large volumes of related data (e.g., hundreds of thousands of rows), the round trips between the application and the database can degrade performance. This is especially true if the network or database latency is high, as multiple smaller queries may take longer than a single, larger query.
References
Below are the references and resources I used to prepare this post:
- https://learn.microsoft.com/en-us/ef/core/performance/advanced-performance-topics?tabs=with-di%2Cexpression-api-with-constant#managing-state-in-pooled-contexts
- https://learn.microsoft.com/en-us/ef/core/querying/single-split-queries
Stay tuned for more posts in this series, where we’ll dive deeper into each technique and best practice.

Leave a comment